【科赛-练习赛】:文本情感分类模型搭建
记录参加科赛举办的文本情感分类模型-练习赛,比赛地址: 文本情感分类模型搭建 | 练习赛
使用TFIDF提前词频特征,利用PyTorch搭建线性预测模型,预测结果AUC 0.8658,截止2019-3-14科赛网公网排名第三。

赛题描述
本练习赛所用数据,是名为「Roman Urdu DataSet」的公开数据集。
这些数据,均为文本数据。原始数据的文本,对应三类情感标签:Positive, Negative, Netural。
本练习赛,移除了标签为Netural的数据样例。因此,练习赛中,所有数据样例的标签为Positive和Negative。
本练习赛的任务是「分类」。「分类目标」是用训练好的模型,对测试集中的文本情感进行预测,判断其情感为「Negative」或者「Positive」。
GitHub
https://github.com/jianchengss/kesci-sentiment-classification.git
提交结果
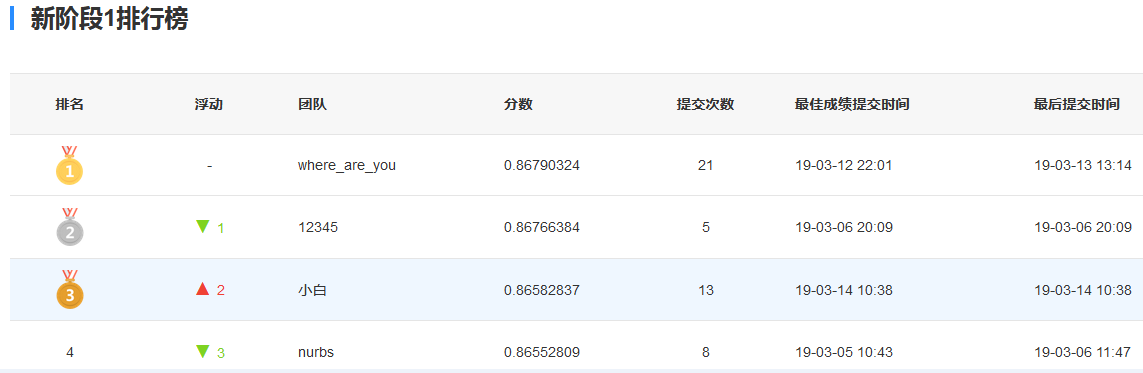
实验结果摘要:
| Date | SHA | Method | AUC-train | AUC-kesci | P | R | F |
|---|---|---|---|---|---|---|---|
| 20190307 | 8225844 | random | - | 0.5057 | - | - | - |
| 20190312 | 05a6790 | rfc-1 | 0.8130 | 0.8054 | 0.7516 | 0.7542 | 0.7520 |
| 20190312 | d4e00a1 | neural_clf | 0.8336 | 0.8357 | 0.7831 | 0.7638 | 0.7728 |
| 20190313 | 9dae25e | forest-2 | 0.8269 | 0.8229 | 0.7602 | 0.7726 | 0.7656 |
| 20190313 | 78f2dc7 | neural_clf | 0.8352 | 0.8412 | 0.7723 | 0.7806 | 0.7762 |
| 20190313 | 14075a4 | soft_max | 0.8369 | 0.8250 | 0.7574 | 0.7911 | 0.7739 |
| 20190313 | a592ca6 | soft_max | 0.8641 | 0.8568 | 0.7930 | 0.8000 | 0.7965 |
| 20190313 | 257fbab | soft_max | 0.8520 | 0.8474 | 0.7368 | 0.8252 | 0.7785 |
| 20190313 | 25b5456 | soft_max | - | 0.8658 | - | - | - |
主要实验过程
公共模块定义
构建公共处理模块有两个目的,一是方便复用,比方说文件的保存与加载、日志的定义;二是跟实验无关的一些中间处理过程。具体代码间GitHub,主要有:
config.py 定义基本配置信息,超参数设置,方便做对比实验;
logger.py 日志配置,实验过程保存至日志文件;
comm.py 数据的加载与保存等公共方法;
数据处理
评价方法
评价方法是评价一个模型好坏的准则,本次比赛测评算法指定为AUC(Area Under the Curve),AUC值越高可以任务情感分类结果越准确。扩展资料:AUC-维基百科 | AUC-百度百科
scikit-learn 已经有AUC的封装:auc = roc_auc_score(y, y_score, average="macro")
新建 report.py 模块,定义Report类如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77class Report():
'''
对预测结果进行评估
'''
def __init__(self, name=''):
'''
初始化
'''
self.name = name
self.f1 = []
self.p1 = []
self.r1 = []
self.f0 = []
self.p0 = []
self.r0 = []
self.auc_scores = []
self.auc = 0
def report_one_folder_by_lable(self, y, y_hat):
'''
中间结果
'''
f1_1 = metrics.f1_score(y, y_hat, pos_label=1)
p_1 = metrics.precision_score(y, y_hat, pos_label=1)
r_1 = metrics.recall_score(y, y_hat, pos_label=1)
f1_0 = metrics.f1_score(y, y_hat, pos_label=0)
p_0 = metrics.precision_score(y, y_hat, pos_label=0)
r_0 = metrics.recall_score(y, y_hat, pos_label=0)
self.f1.append(f1_1)
self.p1.append(p_1)
self.r1.append(r_1)
self.f0.append(f1_0)
self.p0.append(p_0)
self.r0.append(r_0)
logger.info("0 result p: {:.4f} r: {:.4f} f {:.4f}".format(p_0, r_0, f1_0))
logger.info("1 result p: {:.4f} r: {:.4f} f {:.4f}".format(p_1, r_1, f1_1))
return p_1
def report_one_folder(self, y, predict_proba, threshold=0.5):
'''
中间结果
'''
logger.info(self.name)
y_hat = [1 if score[1] >= threshold else 0 for score in predict_proba]
p_1 = self.report_one_folder_by_lable(y, y_hat)
# auc evaluate
y_score = predict_proba[:, 1]
auc = roc_auc_score(y, y_score, average="macro")
self.auc_scores.append(auc)
logger.info("AUC score: {:.4f}".format(auc))
self.auc = np.mean(self.auc_scores)
return auc
def report_final_result(self):
'''
最终结果
'''
logger.info(self.name)
logger.info(
"0 avg result p: {:.4f} r: {:.4f} f {:.4f}".format(np.mean(self.p0), np.mean(self.r0), np.mean(self.f0)))
logger.info(
"1 avg result p: {:.4f} r: {:.4f} f {:.4f}".format(np.mean(self.p1), np.mean(self.r1), np.mean(self.f1)))
if len(self.auc_scores) > 0:
ave_auc = np.mean(self.auc_scores)
logger.info(
"AUC avg score: {:.4f}".format(ave_auc))
return ave_auc
return np.mean(self.p1)
特征提取
新建专门的特征提取模块,命名为:feature.py,代码及解释如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
import config
import word_vec
from logger import logger
class TFIDF():
'''
提取文本的TFIDF特征
'''
def __init__(self, data, min_df=1):
'''
初始化并拟合数据集
:param data:训练集文本
'''
self.data = data
logger.info('init TfidfVectorizer')
self.tfidf = TfidfVectorizer(min_df=min_df)
logger.info('fitting Tfidf...')
self.train_vec = self.tfidf.fit_transform(data).toarray()
logger.info('end')
def transform(self, data):
'''
拟合新的数据集
:param data: 测试集文本
:return:
'''
return self.tfidf.transform(data).toarray()
class Feature():
'''
特征提取的封装类
'''
def __init__(self):
import comm
# 加载训练集和测试集数据
self.train_data = comm.load_df(config.train_data_path)
self.test_data = comm.load_df(config.test_data_path)
self.test_ids = self.test_data["ID"] # 测试集中所有的id
self.y = self.get_target() # 训练集中的情感标签
self.train_features = []
self.test_features = []
# 提取TFIDF特征
train_vec, test_vec = self.tfidf_vec()
self.train_features.append(pd.DataFrame(train_vec))
self.test_features.append(pd.DataFrame(test_vec))
# train_word_vec, test_word_vec = self.word_vec() # 加了会很低
# self.train_features.append(pd.DataFrame(train_word_vec))
# self.test_features.append(pd.DataFrame(test_word_vec))
self.X = pd.concat(self.train_features, axis=1)
self.test_X = pd.concat(self.test_features, axis=1)
logger.info("Shape of train X: {}".format(self.X.shape))
logger.info("Shape of test X: {}".format(self.test_X.shape))
logger.info("Shape of y: {}".format(self.y.shape))
def get_target(self):
def get_lable(label):
if label == 'Positive':
return 1 # Positive 用1表示
else:
return 0
# 将训练集中的标签用 0 1表示
self.train_data['y'] = self.train_data.apply(lambda x: get_lable(x['label']), axis=1)
return self.train_data['y'].values.astype('int')
def tfidf_vec(self):
logger.info("start collect tfidf vec.")
# 用训练集初始化TFIDF
tfidf = TFIDF(self.train_data['review'], min_df=config.tfidf_min_df)
train_vec = tfidf.train_vec
# 提取测试集的TFIDF特征
test_vec = tfidf.transform(self.test_data['review'])
logger.info("shape of trian tfidf: {}".format(train_vec.shape))
logger.info("shape of test tfidf: {}".format(test_vec.shape))
return train_vec, test_vec
def word_vec(self):
'''
提取文本中的词向量表示
:return: 训练集词向量,测试集词向量
'''
logger.info("word vec")
train_word_vec = word_vec.get_word_vec(self.train_data['review'])
test_word_vec = word_vec.get_word_vec(self.test_data['review'])
logger.info("shape of trian word_vec: {}".format(train_word_vec.shape))
logger.info("shape of test word_vec: {}".format(test_word_vec.shape))
self.voc = word_vec.voc
return train_word_vec, test_word_vec
训练过程
新建训练模块,命名为:train.py,代码及解释如下:
分类器的定义
1 | classfiers = {} |
训练过程
1 |
|
预测过程
模型训练完成以后就可以使用训练好的模型预测测试文件中的情感分类,新建 predict.py ,代码和解释如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import pandas as pd
import comm
from feature import Feature
# 使用的模型文件
model_path = "./submissions/model_neural_clf_0.8352"
reslut_path = model_path.replace('model', 'reslut').replace('0.', '')
reslut_path = reslut_path + ".csv" # 结果保存路径
model = comm.load_file(model_path) # 加载模型
feature = Feature()
test_feature = feature.test_X # 测试文件特征
ids = feature.test_ids
# 预测过程,结果为两个label的概率
predict_proba = model.predict_proba(test_feature)
proba = predict_proba[:, 1] # 这里只取1的概率
data = [] # 最终结果
assert len(ids) == len(proba)
for id, p in zip(ids, proba):
data.append([id, p])
result = pd.DataFrame(data, columns=['ID', "Pred"])
comm.dump_submission(result, path=reslut_path)
全部实验项目代码见 GitHub
关键字:
kesci,competition,sentiment,PyTorch原载地址:https://www.jiancheng.ai/2019/03/15/kesci-sentiment-classification/
转载请注明出处!
原文作者: Jason Wang
原文链接: https://jiancheng.ai/2019/03/15/kesci-sentiment-classification/
版权声明: 转载请注明出处(必须保留作者署名及链接)